PMML 2.0 -- Data flow
PMML defines a variety of specific mining models such as for tree classification, neural networks, regression, etc. Equally important, there are also definitions which are common to all models, in order to describe the input data itself and generic transformations which can be applied to the input data before the model itself is evaluated. The following list describes the building blocks for the data definition and for data transformations including the corresponding data flow.
- The DataDictionary describes the data 'as is', that's the raw input data. The DataDictionary refers to the original data and defines how the mining model interprets the data, e.g., as categorical, or numerical, and the range of valid values may be restricted.
- The MiningSchema defines an interface to the user of PMML models. It lists all fields which are used as input to the computations in the mining model. The mining model may internally require further derived values that depend on the input values, but these derived values are not part of the MiningSchema. The derived values are defined in the transformations block. The MiningSchema also defines which values are regarded as outliers, which weighting is applied to a field, e.g., for clustering. Some models may have 'supplementary' fields.
- Input fields as specified in the MiningSchema refer to fields in the data dictionary but not to derived fields because a user of a model is not required to perform the normalizations.
- Various types of transformations are defined such as normalization of numbers to a range [0..1] or discretization of continuous fields. These transformations convert the original values to internal values as they are required by the mining model such as an input neuron of a network model.
- If a PMML model contains transformations a user is not required to take care of these normalizations. The MiningSchema lists the input fields which refer to the non-normalized original values, the user presents these fields as input to the model.
- The transformations in PMML are intended to cover expressions that were generated by a mining technique. A complete mining project usually needs many other preprocessing steps which may have to be defined manually. PMML 2.0 does not provide a complete language for this full preprocessing. These data preparation steps must be performed before feeding the values into a PMML consumer.
- If a PMML document contains multiple models then sharing definitions of normalizations could save space in the document. That's the same idea as for having a common data dictionary. Note, the normalizations may still differ between models, i.e., different models may refer to different sets of derived fields.
- A derived value, defined by a normalization, can be input for another transformation. E.g. a neural network model could have a linear normalization defined on a log-transformed input field 'income'.
- The specific definitions of models such as tree classification or neural network may refer to fields listed in the MiningSchema or to derived fields which can be computed from the MiningSchema-fields (incl. transitive closure).
- The statistics and the specific model can refer to fields in the MiningSchema but also to transformed fields. If there is a replacement value defined for missing values, the statistics refer to the values before the missing values are replaced.
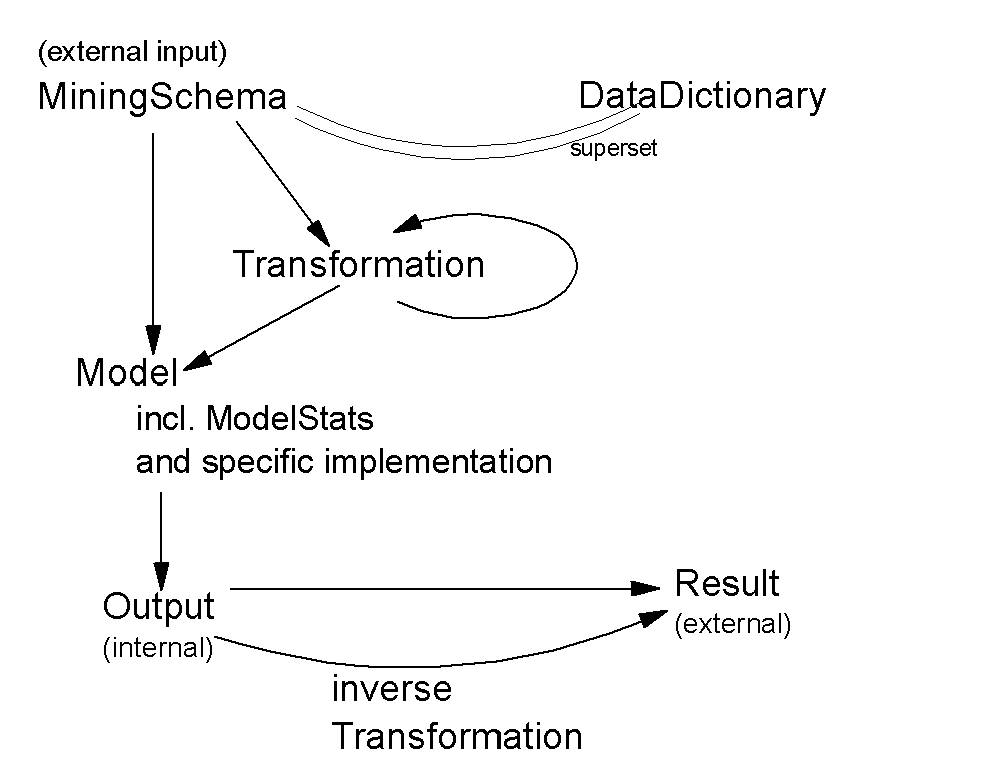
The output of a model always depends on the specific kind of model, e.g. it may by defined by a leave node in a tree or by output neurons in a neural network. The final result, such as a predicted class and a probability, are computed from the output of the model. If a neural network is used for predicting numeric values then the output value of the network usually needs to be denormalized into the original domain of values. Fortunately, this denormalization can use the same kind of transformation types. The PMML consumer system will automatically compute the inverse mapping.
Note that the fields in the tranformation dictionary depend on input from fields in the mining schema. The static structure of a PMML model can be different from the dynamic data flow. The mining schema is part of a model but the transformation dictionary is a shared element outside of models. This works fine because every field in the mining schema of a model is also represented in the global data dictionary. That is, while parsing the derived fields in the transformation dictionary, the information in a specific mining schema is not needed. The input in a derived fields always refers to fields in the data dictionary or in the transformation dictionary itself.