|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
PMML 4.4.1 - Transformation Dictionary and Derived FieldsAt various places the mining models use simple functions in order to map user data to values that are easier to use in the specific model. For example, neural networks internally work with numbers, usually in the range from 0 to 1. Numeric input data are mapped to the range [0..1], and categorical fields are mapped to series of 0/1 indicators. PMML defines various kinds of simple data transformations:
The corresponding XML elements appear as content of a surrounding markup
The transformations in PMML do not cover the full set of preprocessing functions which may be needed to collect and prepare the data for mining. There are too many variations of preprocessing expressions. Instead, the PMML transformations represent expressions that are created automatically by a mining system. A typical example is the normalization of input values in neural networks. Similarly, a discretization might be constructed by a mining system that computes quantile ranges in order to transform skewed data. <xs:group name="EXPRESSION"> <xs:choice> <xs:element ref="Constant"/> <xs:element ref="FieldRef"/> <xs:element ref="NormContinuous"/> <xs:element ref="NormDiscrete"/> <xs:element ref="Discretize"/> <xs:element ref="MapValues"/> <xs:element ref="TextIndex"/> <xs:element ref="Apply"/> <xs:element ref="Aggregate"/> <xs:element ref="Lag"/> </xs:choice> </xs:group> <xs:element name="TransformationDictionary"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="DefineFunction" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="DerivedField" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="LocalTransformations"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="DerivedField" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="DerivedField"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:group ref="EXPRESSION"/> <xs:element ref="Value" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="name" type="FIELD-NAME"/> <xs:attribute name="displayName" type="xs:string"/> <xs:attribute name="optype" type="OPTYPE" use="required"/> <xs:attribute name="dataType" type="DATATYPE" use="required"/> </xs:complexType> </xs:element> If a The The transformation expression in the content of The attribute optype is needed in order to eliminate cases where
the resulting type is not known. If there is a value mapping in a
But it is not known whether"cat" -> "0.1" "dog" -> "0.2" "elephant" -> "0.3" etc. 0.1 has to be interpreted
as a number or as a string (=categorical value). Hence optype is
required in order to make parsing and interpretation of models simpler.
A ConstantConstant values can be used in expressions which have multiple arguments.
The actual value of a constant is given by the content of the element. For
example, If the missing attribute is true, the constant will be taken as a missing value, regardless of the content. In addition to the above the following three values are recognized and taken as equivalent to their IEEE values (see https://www.w3.org/TR/2012/REC-xmlschema11-2-20120405/#float):
A Brief Summary of Operations Involving Infinite NumbersIt should be noted that infinity is not single number, but a class of numbers. Thus, infinity times two is infinity, but the first infinity is not equal to the second. This is reflected in rules detailed below.
<xs:element name="Constant"> <xs:complexType> <xs:simpleContent> <xs:extension base="xs:string"> <xs:attribute name="dataType" type="DATATYPE"/> <xs:attribute name="missing" type="xs:boolean" default="false"/> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> FieldRefField references are simply pass-throughs to fields previously defined in
the <xs:element name="FieldRef"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="field" type="FIELD-NAME" use="required"/> <xs:attribute name="mapMissingTo" type="xs:string"/> </xs:complexType> </xs:element> A missing input will produce a missing result. The optional attribute mapMissingTo may be used to map a missing result to the value specified by the attribute. If the attribute is not present, the result remains missing. NormalizationThe elements for normalization provide a basic framework for mapping input
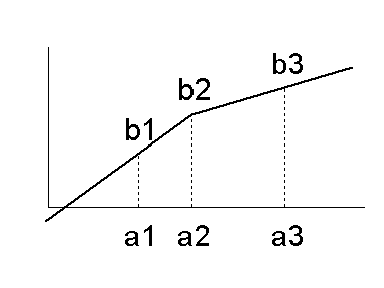
values to specific value ranges, usually the numeric range <xs:element name="NormContinuous"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="LinearNorm" minOccurs="2" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="mapMissingTo" type="NUMBER"/> <xs:attribute name="field" type="FIELD-NAME" use="required"/> <xs:attribute name="outliers" type="OUTLIER-TREATMENT-METHOD" default="asIs"/> </xs:complexType> </xs:element> <xs:element name="LinearNorm"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="orig" type="NUMBER" use="required"/> <xs:attribute name="norm" type="NUMBER" use="required"/> </xs:complexType> </xs:element> NormContinuous: defines how to normalize an input field by
piecewise linear interpolation. The mapMissingTo attribute
defines the value the output is to take if the input is missing.
If the The sequence of LinearNorm elements defines a sequence of points
for a stepwise linear interpolation function. The sequence must contain at
least two elements. Within NormContinous the elements
b1+ ( x-a1)/(a2-a1)*(b2-b1) for a1 ≤ x ≤ a2.
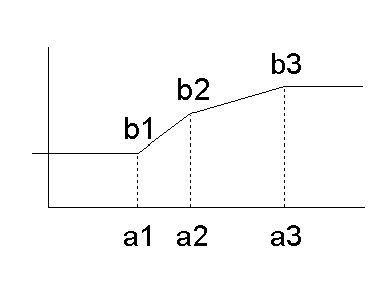
Missing input values are mapped to missing output. asIs: Extrapolates the normalization from the nearest interval. asMissingValues: Maps to a missing value. asExtremeValues: Maps to the next value from the nearest interval so that the function is continuous. The graph below depicts a mapping where outliers are mapped using
<NormContinuous field="X"> <LinearNorm orig="0" norm="-m/s"/> <LinearNorm orig="m" norm="0"/> </NormContinuous> In this example we assume that outliers are treated "asIs". Normalize discrete valuesMany mining models encode string values into numeric values in order to perform mathematical computations. For example, regression and neural network models often split categorical and ordinal fields into multiple dummy fields. This kind of normalization is supported in PMML by the element NormDiscrete. <xs:element name="NormDiscrete"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="field" type="FIELD-NAME" use="required"/> <xs:attribute name="value" type="xs:string" use="required"/> <xs:attribute name="mapMissingTo" type="NUMBER"/> </xs:complexType> </xs:element> An element (f, v) defines that the unit has value The set of If the input value is missing and the attribute
mapMissingTo is not specified then the result is a missing value as
well. If the input value is missing and the attribute DiscretizationDiscretization of numerical input fields is a mapping from continuous to discrete values using intervals. <xs:element name="Discretize"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="DiscretizeBin" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="field" type="FIELD-NAME" use="required"/> <xs:attribute name="mapMissingTo" type="xs:string"/> <xs:attribute name="defaultValue" type="xs:string"/> <xs:attribute name="dataType" type="DATATYPE"/> </xs:complexType> </xs:element> <xs:element name="DiscretizeBin"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="Interval"/> </xs:sequence> <xs:attribute name="binValue" type="xs:string" use="required"/> </xs:complexType> </xs:element> The attribute field defines the name of the input field. The
elements DiscretizeBin define a set of mappings from an
intervali to a binValuei. The value of
the Two intervals may be mapped to the same categorical value but the mapping for each numerical input value must be unique, i.e., the intervals must be disjoint. The intervals should cover the complete range of input values. Decision table for Discretize('*' stands for any combination)
Example: A definition such as: <Discretize field="Profit">
<DiscretizeBin binValue="negative">
<Interval closure="openOpen" rightMargin="0"/>
<!-- left margin is -infinity by default -->
</DiscretizeBin>
<DiscretizeBin binValue="positive">
<Interval closure="closedOpen" leftMargin="0"/>
<!-- right margin is +infinity by default -->
</DiscretizeBin>
</Discretize>
takes the field Profit as input and maps values less than
In SQL this definition corresponds to a
Example: <DerivedField name="Age_mis" displayName="Age missing or not" optype="categorical" dataType="string"> <Discretize field="Age" mapMissingTo="Missing" defaultValue="Not missing"/> </DerivedField> Map ValuesAny discrete value can be mapped to any possibly different discrete value
by listing the pairs of values. This list is implemented by a table, so it
can be given inline by a sequence of XML markups or by a reference to an
external table. The same technique is used for a <xs:element name="MapValues"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:element minOccurs="0" maxOccurs="unbounded" ref="FieldColumnPair"/> <xs:choice minOccurs="0"> <xs:element ref="TableLocator"/> <xs:element ref="InlineTable"/> </xs:choice> </xs:sequence> <xs:attribute name="mapMissingTo" type="xs:string"/> <xs:attribute name="defaultValue" type="xs:string"/> <xs:attribute name="outputColumn" type="xs:string" use="required"/> <xs:attribute name="dataType" type="DATATYPE"/> </xs:complexType> </xs:element> <xs:element name="FieldColumnPair"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="field" type="FIELD-NAME" use="required"/> <xs:attribute name="column" type="xs:string" use="required"/> </xs:complexType> </xs:element> The types InlineTable and TableLocator are defined in the Taxonomy schema. The Different string values can be mapped to one value but it is an error if the table entries used for matching are not unique. The value mapping may be partial. I.e., if an input value does not match a value in the mapping table, then the result can be a missing value. See the decision table below for the possible combinations. Decision table for MapValues('*' stands for any combination)
Example: A definition such as <MapValues outputColumn="longForm">
<FieldColumnPair field="gender" column="shortForm"/>
<InlineTable>
<row><shortForm>m</shortForm><longForm>male</longForm>
</row>
<row><shortForm>f</shortForm><longForm>female</longForm>
</row>
</InlineTable>
</MapValues>
maps abbreviation from the field gender to their corresponding full words. That is, m is mapped to male and f is mapped to female. In SQL this definition corresponds to a CASE expression
Example: Here is an example for the multi-dimensional case, mapping from state and band to salary:
Respective PMML would look like this: <DerivedField dataType="double" optype="continuous">
<MapValues outputColumn="out" dataType="integer">
<FieldColumnPair field="BAND" column="band"/>
<FieldColumnPair field="STATE" column="state"/>
<InlineTable>
<row>
<band>1</band>
<state>MN</state>
<out>10000</out>
</row>
<row>
<band>1</band>
<state>IL</state>
<out>12000</out>
</row>
<row>
<band>1</band>
<state>NY</state>
<out>20000</out>
</row>
<row>
<band>2</band>
<state>MN</state>
<out>20000</out>
</row>
<row>
<band>2</band>
<state>IL</state>
<out>23000</out>
</row>
<row>
<band>2</band>
<state>NY</state>
<out>30000</out>
</row>
</InlineTable>
</MapValues>
</DerivedField>
Example: TheMapValues element can be used to create
missing value indicators for categorical variables. In this case, only one
FieldColumnPair needs to be specified and the column
attribute can be omitted.
<DerivedField name="LSTROPEN_MIS" optype="categorical" dataType="string">
<MapValues mapMissingTo="Missing" defaultValue="Not missing" outputColumn="none">
<FieldColumnPair field="LSTROPEN" column="none"/>
</MapValues>
</DerivedField>
Extracting term frequencies from textTo leverage textual input in a PMML model, we can use a TextIndex expression to extract frequency information from the text input field, for a given term. The TextIndex element fully configures how the text input should be indexed, including case sensitivity, normalization and other settings. It has a single EXPRESSION element nested within containing the term value to look for, which will usually be a simple Constant. <xs:element name="TextIndex"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="TextIndexNormalization" minOccurs="0" maxOccurs="unbounded"/> <xs:group ref="EXPRESSION"/> </xs:sequence> <xs:attribute name="textField" type="FIELD-NAME" use="required"/> <xs:attribute name="localTermWeights" default="termFrequency"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:enumeration value="termFrequency"/> <xs:enumeration value="binary"/> <xs:enumeration value="logarithmic"/> <xs:enumeration value="augmentedNormalizedTermFrequency"/> </xs:restriction> </xs:simpleType> </xs:attribute> <xs:attribute name="isCaseSensitive" type="xs:boolean" default="false"/> <xs:attribute name="maxLevenshteinDistance" type="xs:integer" default="0"/> <xs:attribute name="countHits" default="allHits"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:enumeration value="allHits"/> <xs:enumeration value="bestHits"/> </xs:restriction> </xs:simpleType> </xs:attribute> <xs:attribute name="wordSeparatorCharacterRE" type="xs:string" default="\s+"/> <xs:attribute name="tokenize" type="xs:boolean" default="true"/> </xs:complexType> </xs:element> The TextIndex element fully configures how the text in textField should be processed and translated into a frequency metric for a particular term of interest. The actual frequency metric to be returned is defined through the localTermWeights attribute. The options are described in more detail by T. G. Kolda and D. P. O'Leary, A Semi-Discrete Matrix Decomposition of Latent Semantic Indexing in Information Retrieval, ACM Transactions on Information Systems, Volume 16, 1998, pages 322-346.
The isCaseSensitive attribute defines whether or not the case used in the text input should exactly match the case usage in the terms for which the frequency should be returned. Through maxLevenshteinDistance, small spelling mistakes can be accommodated, accepting a certain number of character additions, ommissions or replacements. See also this article. To capture compound words more easily, the wordSeparatorCharacterRE attribute can be used to pass a regular expression containing possible word separator characters. For example, if "[\s\-]" is passed, the strings "user-friendly" and "user friendly" would both match the term "user friendly". More complex normalization operations can be addressed through the TextIndexNormalization element. Note that the default value for attribute wordSeparatorCharacterRE means one or more spaces. The wordSeparatorCharacterRE attribute applies to the given text unless attribute tokenize is set to "false". When attribute tokenize is set to "true", which is its default value, wordSeparatorCharacterRE should be applied to the text input field as well as the given term. This process will result in one or more tokens for which the leading and trailing punctuations should then be removed. The punctuation-free tokenized term can then be described by one word or a sequence of words, depending on the number or resulting tokens. To calculate a term's frequency, count number of "hits" in the text for the particular term according to the value of countHits. A "hit" is defined as an occurrence of the term in the input text, meeting the case requirements defined through isCaseSensitive within the maxLevenshteinDistance. For example, if the given term is defined as "brown fox" and the input text is "The quick browny foxy jumps over the lazy dog. The brown fox runs away and to be with another brown foxy.". If attribute maxLevenshteinDistance is set to 1, the text "browny foxy" will not be considered a "hit" since its Levenshtein distance is 2 (the sum of the Levenshtein distances for words "browny" and "foxy" after the input text has been tokenized). The text "brown fox" that is retrieved next is a "hit" since the Levenshtein distance is 0. The text "brown foxy." is also a "hit" since the Levenshtein distance is 1. Note that the punctuation has been removed before computing the Levenshtein distance. The number of "hits" in the text can be counted in two different ways. These are:
For example, if the input text is defined as "I have a doog. My dog is white. The doog is friendly" and the attribute maxLevenshteinDistance is set to 1, the number of hits for term "dog" will be 3 if attribute countHits is set to "allHits" and 1 if it is set to "bestHits". An example
<MiningSchema>
<MiningField name="myTextField"/>
...
</MiningSchema>
<LocalTransformations>
<DerivedField name="sunFrequency">
<TextIndex textField="myTextField" localTermWeights="termFrequency"
isCaseSensitive="false" maxLevenshteinDistance="1" >
<Constant>sun</Constant>
</TextIndex>
</DerivedField>
...
In the above example, the DerivedField sunFrequency will contain the number of hits for the term "sun" in the input field myTextField, regardless of case and with at most one spelling mistake. For example, if the value of myTextField is "The Sun was setting while the captain's son reached the bounty island, minutes after their ship had sunk to the bottom of the ocean", sunFrequency will be 3 as "Sun", "son" and "sunk" all match the term "sun" with a Levenshtein distance of 0 or 1. If the maximum Levenshtein distance were to be 0, only "Sun" would have matched. Predictive models using text as an input are likely to be looking for more than a single term. Therefore, it is often convenient to define the TextIndex element just once inside a DefineFunction element and then invoke it with Apply elements as shown in the following example.
...
<TransformationDictionary>
<DefineFunction name="myIndexFunction">
<ParameterField name="text"/>
<ParameterField name="term"/>
<TextIndex textField="text" localTermWeights="termFrequency"
isCaseSensitive="false" maxLevenshteinDistance="1" >
<FieldRef field="term"/>
</TextIndex>
</DefineFunction>
</TransformationDictionary>
...
<MiningSchema>
<MiningField name="myTextField"/>
...
</MiningSchema>
<LocalTransformations>
<DerivedField name="sunFrequency">
<Apply function="myIndexFunction">
<FieldRef field="myTextField"/>
<Constant>sun</Constant>
</Apply>
</DerivedField>
<DerivedField name="rainFrequency">
<Apply function="myIndexFunction">
<FieldRef field="myTextField"/>
<Constant>rain</Constant>
</Apply>
</DerivedField>
<DerivedField name="windFrequency">
<Apply function="myIndexFunction">
<FieldRef field="myTextField"/>
<Constant>wind</Constant>
</Apply>
</DerivedField>
...
Normalizing text inputWhile the Levenshtein distance is useful to cover small spelling mistakes, it's not necessarily suitable to capture different forms of the same term, such as cases of nouns, conjugations of verbs or even synonyms. One or more TextIndexNormalization elements can be nested within a TextIndex to normalize input text into a more term-friendly form. <xs:element name="TextIndexNormalization"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:choice minOccurs="0"> <xs:element ref="TableLocator"/> <xs:element ref="InlineTable"/> </xs:choice> </xs:sequence> <xs:attribute name="inField" type="xs:string" default="string"/> <xs:attribute name="outField" type="xs:string" default="stem"/> <xs:attribute name="regexField" type="xs:string" default="regex"/> <xs:attribute name="recursive" type="xs:boolean" default="false"/> <xs:attribute name="isCaseSensitive" type="xs:boolean"/> <xs:attribute name="maxLevenshteinDistance" type="xs:integer"/> <xs:attribute name="wordSeparatorCharacterRE" type="xs:string"/> <xs:attribute name="tokenize" type="xs:boolean"/> </xs:complexType> </xs:element> A TextIndexNormalization element offers more advanced ways of normalizing text input into a more controlled vocabulary that corresponds to the terms being used in invocations of this indexing function. The normalization operation is defined through a translation table, specified through a TableLocator or InlineTable element. If an input in the inField column is encountered in the text, it is replaced by the value in the outField column. If there is a regexField column and its value for that row is true, the string in the inField column should be treated as a PCRE regular expression. For regular expression rows, attributes maxLevenshteinDistance and isCaseSentive are ignored. By default, the translation table is applied once, applying each row once from top to bottom. If the recursive flag is set to true, the normalization table is reapplied until none of its rows causes a change to the input text. If multiple TextIndexNormalization elements are defined, they are applied in the order in which they appear. That is, if more than one TextIndexNormalization element is defined, the output of applying a TextIndexNormalization element will serve as the input to the next TextIndexNormalization element. This enables, for example, to have a first normalization step to take care of morphological translations to get each word into some base form (stemming), a second normalization step to combine synonyms by applying some sort of taxonomy and perhaps a third step to look for particular sequences of normalized tokens. By default, the TextIndexNormalization element inherits the values for isCaseSensitive, maxLevenshteinDistance, wordSeparatorCharacterRE and tokenize from the TextIndex element, but they can be overridden per TextIndexNormalization element. For each TextIndexNormalization element, wordSeparatorCharacterRE does not apply to the inField and outField columns for regular expression rows. However, it applies to both inField and outField for non-regular expression rows. An example with normalization
...
<TransformationDictionary>
<DefineFunction name="myIndexFunction" optype="continuous">
<ParameterField name="reviewText"/>
<ParameterField name="term"/>
<TextIndex textField="reviewText" localTermWeights="binary" isCaseSensitive="false">
<TextIndexNormalization inField="string" outField="stem" regexField="regex">
<InlineTable>
<row>
<string>interfaces?</string>
<stem>interface</stem>
<regex>true</regex>
</row>
<row>
<string>is|are|seem(ed|s?)|were</string>
<stem>be</stem>
<regex>true</regex>
</row>
<row>
<string>user friendl(y|iness)</string>
<stem>user_friendly</stem>
<regex>true</regex>
</row>
</InlineTable>
</TextIndexNormalization>
<TextIndexNormalization inField="re" outField="feature" regexField="regex">
<InlineTable>
<row>
<re>interface be (user_friendly|well designed|excellent)</re>
<feature>ui_good</feature>
<regex>true</regex>
</row>
</InlineTable>
</TextIndexNormalization>
<FieldRef field="term"/>
</TextIndex>
</DefineFunction>
</TransformationDictionary>
...
<MiningSchema>
<MiningField name="Review"/>
...
</MiningSchema>
<LocalTransformations>
<DerivedField name="isGoodUI">
<Apply function="myIndexFunction">
<FieldRef field="Review"/>
<Constant>ui_good</Constant>
</Apply>
</DerivedField>
...
For example, when processing the text fragment "Testing the app for a few days convinced me the interfaces are excellent!", applying the first normalization block yields "Testing the app for a few days convinced me the interface be excellent!". Applying the second block then yields "Testing the app for a few days convinced me the ui_good!", which will produce a frequency value of 1 for the "isGoodUI" field. AggregationsAssociation rules and sequences refer to sets of items. These sets can be
defined by an aggregation over sets of input records. The records are grouped
together by one of the fields and the values in this grouping field partition
the sets of records for an aggregation. This corresponds to the conventional
aggregation in SQL with a <xs:element name="Aggregate"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="field" type="FIELD-NAME" use="required"/> <xs:attribute name="function" use="required"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:enumeration value="count"/> <xs:enumeration value="sum"/> <xs:enumeration value="average"/> <xs:enumeration value="min"/> <xs:enumeration value="max"/> <xs:enumeration value="multiset"/> </xs:restriction> </xs:simpleType> </xs:attribute> <xs:attribute name="groupField" type="FIELD-NAME"/> <xs:attribute name="sqlWhere" type="xs:string"/> </xs:complexType> </xs:element> A definition such as: <Aggregate field="item" function="multiset" groupField="transaction"/> builds sets of item values; for each transaction, i.e. for each value in the field transaction there is one set of items. LagA "lag" is here defined as the value of the given input field a fixed number of records prior to the current one, assuming there are that many; and optionally assuming that they are part of the same block of records (aka "case history"), as defined by the values of one or more input fields (the "block specifiers"). If the desired value is not present, for a given record, the lag will be set to missing. Warning!Lags are only meaningful if the data are already sorted in the desired order (normally chronologically within case histories). It should not be assumed that a consumer will do the requisite sorting. <xs:element name="Lag"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> <xs:element ref="BlockIndicator" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="field" type="FIELD-NAME" use="required"/> <xs:attribute name="n" type="xs:positiveInteger" default="1"/> <xs:attribute name="aggregate" default="none"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:enumeration value="none"/> <xs:enumeration value="avg"/> <xs:enumeration value="max"/> <xs:enumeration value="median"/> <xs:enumeration value="min"/> <xs:enumeration value="product"/> <xs:enumeration value="sum"/> <xs:enumeration value="stddev"/> </xs:restriction> </xs:simpleType> </xs:attribute> </xs:complexType> </xs:element> <xs:element name="BlockIndicator"> <xs:complexType> <xs:sequence> <xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/> </xs:sequence> <xs:attribute name="field" type="FIELD-NAME" use="required"/> </xs:complexType> </xs:element>
Simple Lag Example<Lag field="Receipts"/> In this example, the value returned will be that of Receipts in the record immediately prior to the current one, except that on the first record, it will be missing. Slightly More Complex Lag Example<Lag field="Receipts" n="2"/> Here, the value returned will be that of Receipts on the record just before the previous one, except that on the first two records, it will be missing. Example Lag Within a Block
<Lag field="AmtPaid" n="1">
<BlockIndicator field="CustomerID"/>
</Lag>
In this example, the value returned will be that of AmtPaid on the next previous record, if it has the same value of CustomerID as the current one, otherwise it will be missing. Example with Aggregate Operation<Lag field="AmtPaid" n="3" aggregate="sum"/> In this case, the returned value will be the sum of the three previous AmtPaid values. The table below contains a list of records to give more detail. For instance, the result of the lag expression of Record_5 will be '9'. Note that the first record will not contain a value for lag. Record_2 will only contain the sum of the first record and Record_3 will only contain the sum of the first two records.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|