PMML 3.0 - Transformation Dictionary & Derived Fields
At various places the mining models use simple functions in order to map user data to values that are easier to use in the specific model. For example, neural networks internally work with numbers, usually in the range from 0 to 1. Numeric input data are mapped to the range [0..1], and categorical fields are mapped to series of 0/1 indicators. Similarly, Naive Bayes models internally map all input data to categorical values.
PMML defines various kinds of simple data transformations:
- Normalization: map values to numbers, the input can be continuous or discrete.
- Discretization: map continuous values to discrete values.
- Value mapping: map discrete values to discrete values.
- Functions: derive a value by applying a function to one or more parameters
- Aggregation: summarize or collect groups of values, e.g., compute average.
The corresponding XML elements appear as content of a surrounding markup DerivedField. which provides a common element for the various mappings. They can also appear at several places in the definition of specific models such as neural network or Naive Bayes models. Transformed fields have a name such that statistics and the model can refer to these fields.
The transformations in PMML do not cover the full set of preprocessing functions which may be needed to collect and prepare the data for mining. There are too many variations of preprocessing expressions. Instead, the PMML transformations represent expressions that are created automatically by a mining system. A typical example is the normalization of input values in neural networks. Similarly, a discretization might be constructed by a mining system that computes quantile ranges in order to transform skewed data.
<xs:group name="EXPRESSION">
<xs:choice>
<xs:element ref="Constant" />
<xs:element ref="FieldRef" />
<xs:element ref="NormContinuous" />
<xs:element ref="NormDiscrete" />
<xs:element ref="Discretize" />
<xs:element ref="MapValues" />
<xs:element ref="Apply" />
<xs:element ref="Aggregate" />
</xs:choice>
</xs:group>
<xs:element name="TransformationDictionary">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
<xs:element ref="DefineFunction" minOccurs="0" maxOccurs="unbounded" />
<xs:element ref="DerivedField" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="LocalTransformations">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
<xs:element ref="DerivedField" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="DerivedField">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
<xs:group ref="EXPRESSION" />
<xs:element ref="Interval" minOccurs="0" maxOccurs="unbounded" />
<xs:element ref="Value" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="name" type="FIELD-NAME" />
<xs:attribute name="displayName" type="xs:string" />
<xs:attribute name="optype" type="OPTYPE" use="required"/>
<xs:attribute name="dataType" type="DATATYPE" use="required"/>
</xs:complexType>
</xs:element>
|
DerivedFields in the TransformationDictionary or LocalTransformations together with DataFields in the DataDictionary must have unique names. If a DerivedField is contained in TransformationDictionary or LocalTransformations, then the name attribute is required. For DerivedFields which are contained inline in models the name is optional.
The transformation expression in the content of DerivedField defines how the values of the new field are computed.
The attribute optype is needed in order to eliminate cases where the resulting type is not known. If there is a value mapping in a DerivedField, it is not known how to interpret the output. A value mapping might look like this:
"cat" -> "0.1" "dog" -> "0.2" "elephant" -> "0.3" etc.But it is not known whether "0.1" has to be interpreted as a number or as a string (=categorical value). The attribute is required in order to make parsing and interpretation of models simpler.
A DerivedField may have a list of Value elements or alternatively an interval for fields with numeric value range. They define which result values are valid. That is, they refer to values or value ranges after the transformation expression has been applied. For ordinal fields they also define the ordering of the values. The attribute "property" must not be used for Value elements within a DerivedField. That is, the list cannot specify values that are interpreted as missing or invalid.
Constant values and references to other fields can be used in expressions
which have multiple arguments.
The actual value of a constant is given by the content of the element.
For example, <Constant>1.05</Constant> represents the number 1.05.
Field references are used in clustering models
in order to define center coordinates for fields that don't need
further normalization.
<xs:element name="Constant" type="xs:anyType"/>
<xs:element name="FieldRef">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="field" type="FIELD-NAME" use="required" />
</xs:complexType>
</xs:element>
Normalization
The elements for normalization provide a basic framework for mapping input values to specific value ranges, usually the numeric range [0 .. 1]. Normalization is used in neural networks. Similar instances are also used in regression models.
<xs:element name="NormContinuous">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
<xs:element minOccurs="2" maxOccurs="unbounded" ref="LinearNorm" />
</xs:sequence>
<xs:attribute name="field" type="FIELD-NAME" use="required" />
</xs:complexType>
</xs:element>
<xs:element name="LinearNorm">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="orig" type="NUMBER" use="required" />
<xs:attribute name="norm" type="NUMBER" use="required" />
</xs:complexType>
</xs:element>
|
NormContinuous: defines how to normalize an input field by piecewise linear interpolation.
The sequence of LinearNorm elements defines a sequence of points for a stepwise linear interpolation function. The sequence must contain at least two elements. (If LinearNorm is missing then the input field is not normalized.) Within NormContinous the elements LinearNorm must be strictly sorted by ascending value of orig. Given two points (a1, b1) and (a2, b2) such that there is no other point (a3, b3) with a1<a3<a2, then the normalized value is
b1+ ( x-a1)/(a2-a1)*(b2-b1) for a1 <= x <= a2.
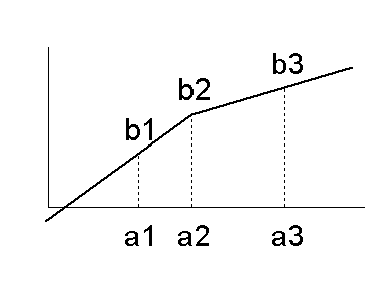
Missing input values are mapped to missing output. If the input value is not within the range [a1..an] then it is treated as an outlier, the specific method for outlier treatment must be provided by the caller. E.g., an outlier could be mapped to a missing value or it could be treated 'as is' by extrapolating the normalization from the nearest interval. The graph above shows the default behavior with an extrapolation for values less than a1 or greater than a3.
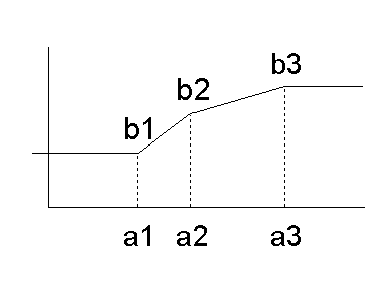
Clarification: The graph below depicts a mapping where outliers are mapped to a minimum or maximum value.
NormContinuous can be used to implement simple normalization functions
such as the "z-score transformation" (X - m ) / s, where m is the mean value
and s is the standard deviation.
<NormContinuous field="X">
<LinearNorm orig="0" norm=" -m/s " />
<LinearNorm orig=" m " norm="0" />
</NormContinuous>
Normalize discrete values
Many mining models encode string values into numeric values in order to perform mathematical computations. For example, regression and neural network models often split categorical and ordinal fields into multiple dummy fields. This kind of normalization is supported in PMML by the element NormDiscrete.
<xs:element name="NormDiscrete">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="field" type="FIELD-NAME" use="required" />
<xs:attribute name="method" fixed="indicator" >
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="indicator" />
<xs:enumeration value="thermometer" />
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="value" type="xs:string" use="required" />
<xs:attribute name="mapMissingTo" type="xs:string" />
</xs:complexType>
</xs:element>
|
With the indicator method, an element (f, v) defines that the unit has value 1.0 if the value of input field f is v, otherwise it is 0.
The set of NormDiscrete instances which refer to a certain input field define a fan-out function which maps a single input field to a set of normalized fields.
If the input value is missing and the attribute 'mapMissingTo' is not specified then the result is a missing value as well. If the input value is missing and the attribute 'mapMissingTo' is specified then the result is the value of the attribute 'mapMissingTo'.Discretization
Discretization of numerical input fields is a mapping from intervals to strings.
<xs:element name="Discretize">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
<xs:element maxOccurs="unbounded" ref="DiscretizeBin" />
</xs:sequence>
<xs:attribute name="field" type="FIELD-NAME" use="required" />
<xs:attribute name="mapMissingTo" type="xs:string" />
<xs:attribute name="defaultValue" type="xs:string" />
</xs:complexType>
</xs:element>
<xs:element name="DiscretizeBin">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
<xs:element ref="Interval" />
</xs:sequence>
<xs:attribute name="binValue" type="xs:string" use="required" />
</xs:complexType>
</xs:element>
|
The attribute field defines the name of the input field. The elements DiscretizeBin define a set of mappings from an Interval_i to a binValue_i. The value of the derived field is binValue_i if the input value is contained in Interval_i for some i.
Two intervals may be mapped to the same categorical value but the mapping for each numerical input value must be unique, i.e., the intervals must be disjoint. The intervals should cover the complete range of input values.
Decision table for Discretize
('*' stands for any combination)| input value | matching interval | defaultValue | mapMissingTo | => | result |
|---|---|---|---|---|---|
| val | Interval_i | * | * | => | binValue_i |
| val | none | someVal | * | => | someVal |
| val | none | not specified | * | => | missing |
| missing | * | * | someVal | => | someVal |
| missing | * | * | not specified | => | missing |
Example: A definition such as:
<Discretize field="Profit">
<DiscretizeBin binValue="negative">
<Interval closure="openOpen" rightMargin="0" />
<!-- left margin is -infinity by default -->
</DiscretizeBin>
<DiscretizeBin binValue="positive">
<Interval closure="closedOpen" leftMargin="0" />
<!-- right margin is +infinity by default -->
</DiscretizeBin>
</Discretize>
In SQL this definition corresponds to a CASE expression
CASE When "Profit" <0 Then 'negative' When "Profit" >=0 Then 'positive' End
Map Values
Any discrete value can be mapped to any possibly different discrete value by listing the pairs of values. This list is implemented by a Table, so it can be given inline by a sequence of XML markups or by a reference to an external table. The same technique is used for a Hierarchy because the tables can become quite large.
<xs:element name="MapValues">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
<xs:element maxOccurs="unbounded" ref="FieldColumnPair" />
<xs:choice>
<xs:element ref="TableLocator" />
<xs:element ref="InlineTable" />
</xs:choice>
</xs:sequence>
<xs:attribute name="mapMissingTo" type="xs:string" />
<xs:attribute name="defaultValue" type="xs:string" />
<xs:attribute name="outputColumn" type="xs:string" use="required" />
</xs:complexType>
</xs:element>
<xs:element name="FieldColumnPair">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="field" type="FIELD-NAME" use="required" />
<xs:attribute name="column" type="xs:string" use="required" />
</xs:complexType>
</xs:element>
|
The types InlineTable and TableLocator are defined in the Taxonomy schema.
Different string values can be mapped to one value but it is an error if the table entries used for matching are not unique. The value mapping may be partial. I.e., if an input value does not match a value in the mapping table, then the result can be a missing value. See the decision table below for the possible combinations.
Decision table for MapValues
('*' stands for any combination)| input value | matching value | defaultValue | mapMissingTo | => | result |
|---|---|---|---|---|---|
| val | in row i | * | * | => | outputColumn in row i |
| val | none | someVal | * | => | someVal |
| val | none | not specified | * | => | missing |
| missing | * | * | someVal | => | someVal |
| missing | * | * | not specified | => | missing |
Example: A definition such as
<MapValues outputColumn="longForm">
<FieldColumnPair field="gender" column="shortForm"/>
<InlineTable>
<row><shortForm>m</shortForm><longForm>male</longForm>
</row>
<row><shortForm>f</shortForm><longForm>female</longForm>
</row>
</InlineTable>
</MapValues>
In SQL this definition corresponds to a CASE expression
CASE "gender" When 'm' Then 'male' When 'f' Then 'female' End
Aggregations
Association rules and sequences refer to sets of items. These sets can be defined by an aggregation over sets of input records. The records are grouped together by one of the fields and the values in this grouping field partition the sets of records for an aggregation. This corresponds to the conventional aggregation in SQL with a 'GROUP BY' clause.
<xs:element name="Aggregate">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="field" type="FIELD-NAME" use="required" />
<xs:attribute name="function" use="required">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="count" />
<xs:enumeration value="sum" />
<xs:enumeration value="average" />
<xs:enumeration value="min" />
<xs:enumeration value="max" />
<xs:enumeration value="multiset" />
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="groupField" type="FIELD-NAME" />
<xs:attribute name="sqlWhere" type="xs:string" />
</xs:complexType>
</xs:element>
|
A definition such as:
<Aggregate field="item" function="multiset" groupField="transaction"/> |
builds sets of item values; for each transaction, i.e. for each value in the field "transaction" there is one set of items.